Semantic Code Search
Semantic Code Search


From Prompt to Product
A strange thing has happened in software development, we’re no longer writing code in the traditional sense. Instead, we describe what we want and ask the machine to write the first draft. Tools like GitHub Copilot, Cursor, Replit, and Devin have changed what it means to build. The keyboard isn’t gone, but it’s quieter. Developers are prompting, guiding, reviewing. Code appears in response to our intent.
This isn’t a distant future. It’s happening now. Describe a function in a comment and Copilot autocompletes it. Open a new file in Cursor and ask for a feature, and it drafts the architecture across files. The role of a developer is less that of a typist, but more akin to a curator or conductor.
But even the best AI tools come with hallucinations; they end up guessing when they should know. Unlike other AI applications, such as a customer support where agents can improvise around vague answers, coding doesn’t tolerate bluffing. The truth in software is explicit. Ask a coding agent to help you with session handling, and it might invent a helper function that doesn’t exist, when the correct one is already defined two files over.
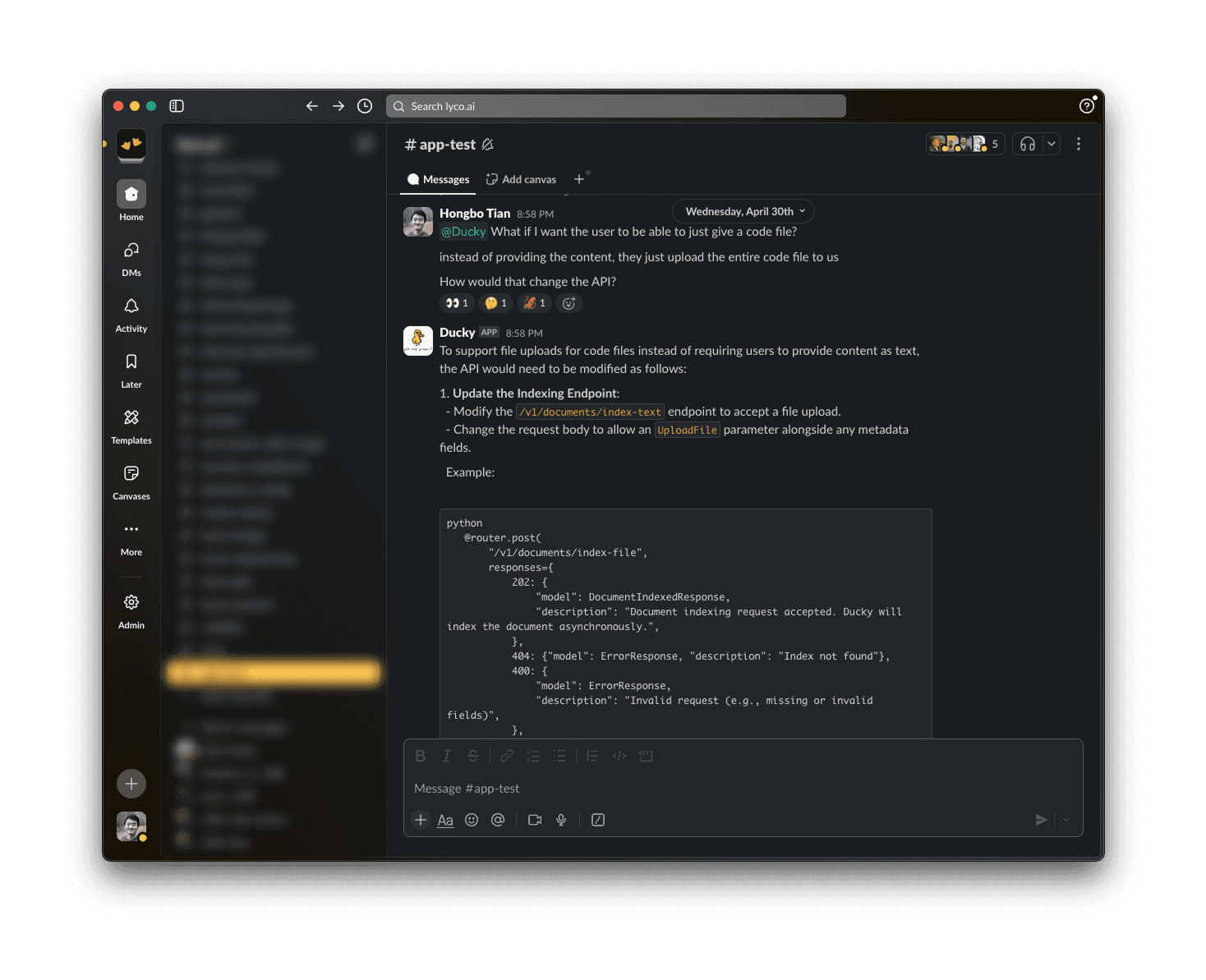
✨Vibe coding✨ is more fun in a public Slack channel
This bottleneck is not in generation, but in awareness. A coding agent can write a brilliant one-liner and then immediately trip over your codebase because it doesn’t remember what it wrote, can’t find what it needs, and has no understanding of how your large codebase works.
This is where semantic code search comes in. It doesn’t just match strings. It finds meaning. Ask “Where are users authenticated?” and it retrieves the right files, even if those exact words never appear. Ask “How is billing handled?” and it surfaces the file with your invoice scheduler. It acts like memory or intuition, the kind of context a smart developer builds over weeks of immersion.
Let’s help the agent stop guessing and give it the context it needs. Traditionally, that would mean stitching together a pipeline of embedding models, chunking logic, and a vector database, just to get basic retrieval working. This is typically fragile and hard to maintain, but Ducky abstracts all of that. We can skip the plumbing, and get semantic code search working in minutes.
Semantic Code Search with Ducky AI
Making your codebase searchable shouldn’t require setting up a vector database or designing a custom pipeline. With Ducky, it takes one script and a few lines of setup.
Here’s how it works.
Step one
Let’s prepare each file into a structured document with metadata so we can use semantic search and apply metadata filters later if we need to narrow things down. Our document looks something like this
{ "content": content, # code content "doc_id": f.relative_to(root), # unique identifier "title": f.name, "metadata": { "root": root, "full_path": f.as_posix(), "file_type": f.suffix, }, "index_name": "code-memory", # data store }
Step two
Ducky supports up to 100 documents in a single upload. If you're working with a larger codebase, you’ll want to split your documents into batches. This keeps indexing smooth and avoids hitting the upload limit.
for i in range(0, len(docs), batch_size): batch = docs[i : i + batch_size] ducky.documents.batch_index(documents=batch)
Step three
Now let’s get Ducky set up.
Create a project and an index — in the example above, we used
code-memoryGet your API key from the project settings
Install the Python SDK
Initialize the client with your API key
ducky = DuckyAI(api_key="DUCKYAI_API_KEY")
Now putting everything together in less than 50 lines of code
import sys from pathlib import Path from duckyai import DuckyAI from typing import List ducky = DuckyAI(api_key='DUCKYAI_API_KEY') def prepare_documents(files: List[Path], root: str) -> List[dict]: """Prepare documents for indexing.""" return [ { "content": content, "doc_id": str(f.relative_to(root)).replace("/", "-").replace(".", "-"), "title": f.name, "metadata": { "root": root, "full_path": f.as_posix(), "file_type": f.suffix, }, "index_name": "code-memory", } for f in files if (content := f.read_text()) ] def batch_index_documents(docs: List[dict], batch_size: int = 100): """Index documents in batches.""" for i in range(0, len(docs), batch_size): print( f"INFO: Indexing batch {i // batch_size + 1} of {len(docs) // batch_size + 1}" ) ducky.documents.batch_index(documents=docs[i : i + batch_size]) if __name__ == "__main__": if len(sys.argv) < 2: sys.exit("Usage: python ingest.py <repo_path>") directory = sys.argv[1] files = list(Path(directory).rglob("*.py")) print(f"Found {len(files)} Python files.") docs = prepare_documents(files, directory) print(f"INFO: Prepared {len(docs)} documents for indexing.") batch_index_documents(docs)
Step four
Once your documents are indexed, you can search across your codebase using natural language. You can do this directly in the developer dashboard or use the SDK to retrieve results in your application.
Here’s how to run a simple query with the Python client:
results = ducky.documents.retrieve( index_name="code-memory", query="how do we track customer usage?", top_k=5, rerank=True, ) for doc in results.documents: print(doc.title) print(doc.metadata)
What’s Next
We’ve made the codebase fully searchable in under 50 lines of code. No infrastructure setup. No model tuning. Just a clean semantic layer that lets you ask real questions about your own code and get useful answers back.
This isn’t just about search. It’s about enabling better tools, tighter feedback loops, and assistants that actually understand the systems they’re working in. If you’re building with AI, retrieval is not a nice-to-have. It’s foundational.
Try it on your own codebase, or check out our other resources
📘 Documentation – for detailed setup, search tuning, and advanced features
🧑🍳 Cookbooks – for practical examples and quick-start guides
From Prompt to Product
A strange thing has happened in software development, we’re no longer writing code in the traditional sense. Instead, we describe what we want and ask the machine to write the first draft. Tools like GitHub Copilot, Cursor, Replit, and Devin have changed what it means to build. The keyboard isn’t gone, but it’s quieter. Developers are prompting, guiding, reviewing. Code appears in response to our intent.
This isn’t a distant future. It’s happening now. Describe a function in a comment and Copilot autocompletes it. Open a new file in Cursor and ask for a feature, and it drafts the architecture across files. The role of a developer is less that of a typist, but more akin to a curator or conductor.
But even the best AI tools come with hallucinations; they end up guessing when they should know. Unlike other AI applications, such as a customer support where agents can improvise around vague answers, coding doesn’t tolerate bluffing. The truth in software is explicit. Ask a coding agent to help you with session handling, and it might invent a helper function that doesn’t exist, when the correct one is already defined two files over.
✨Vibe coding✨ is more fun in a public Slack channel
This bottleneck is not in generation, but in awareness. A coding agent can write a brilliant one-liner and then immediately trip over your codebase because it doesn’t remember what it wrote, can’t find what it needs, and has no understanding of how your large codebase works.
This is where semantic code search comes in. It doesn’t just match strings. It finds meaning. Ask “Where are users authenticated?” and it retrieves the right files, even if those exact words never appear. Ask “How is billing handled?” and it surfaces the file with your invoice scheduler. It acts like memory or intuition, the kind of context a smart developer builds over weeks of immersion.
Let’s help the agent stop guessing and give it the context it needs. Traditionally, that would mean stitching together a pipeline of embedding models, chunking logic, and a vector database, just to get basic retrieval working. This is typically fragile and hard to maintain, but Ducky abstracts all of that. We can skip the plumbing, and get semantic code search working in minutes.
Semantic Code Search with Ducky AI
Making your codebase searchable shouldn’t require setting up a vector database or designing a custom pipeline. With Ducky, it takes one script and a few lines of setup.
Here’s how it works.
Step one
Let’s prepare each file into a structured document with metadata so we can use semantic search and apply metadata filters later if we need to narrow things down. Our document looks something like this
{ "content": content, # code content "doc_id": f.relative_to(root), # unique identifier "title": f.name, "metadata": { "root": root, "full_path": f.as_posix(), "file_type": f.suffix, }, "index_name": "code-memory", # data store }
Step two
Ducky supports up to 100 documents in a single upload. If you're working with a larger codebase, you’ll want to split your documents into batches. This keeps indexing smooth and avoids hitting the upload limit.
for i in range(0, len(docs), batch_size): batch = docs[i : i + batch_size] ducky.documents.batch_index(documents=batch)
Step three
Now let’s get Ducky set up.
Create a project and an index — in the example above, we used
code-memoryGet your API key from the project settings
Install the Python SDK
Initialize the client with your API key
ducky = DuckyAI(api_key="DUCKYAI_API_KEY")
Now putting everything together in less than 50 lines of code
import sys from pathlib import Path from duckyai import DuckyAI from typing import List ducky = DuckyAI(api_key='DUCKYAI_API_KEY') def prepare_documents(files: List[Path], root: str) -> List[dict]: """Prepare documents for indexing.""" return [ { "content": content, "doc_id": str(f.relative_to(root)).replace("/", "-").replace(".", "-"), "title": f.name, "metadata": { "root": root, "full_path": f.as_posix(), "file_type": f.suffix, }, "index_name": "code-memory", } for f in files if (content := f.read_text()) ] def batch_index_documents(docs: List[dict], batch_size: int = 100): """Index documents in batches.""" for i in range(0, len(docs), batch_size): print( f"INFO: Indexing batch {i // batch_size + 1} of {len(docs) // batch_size + 1}" ) ducky.documents.batch_index(documents=docs[i : i + batch_size]) if __name__ == "__main__": if len(sys.argv) < 2: sys.exit("Usage: python ingest.py <repo_path>") directory = sys.argv[1] files = list(Path(directory).rglob("*.py")) print(f"Found {len(files)} Python files.") docs = prepare_documents(files, directory) print(f"INFO: Prepared {len(docs)} documents for indexing.") batch_index_documents(docs)
Step four
Once your documents are indexed, you can search across your codebase using natural language. You can do this directly in the developer dashboard or use the SDK to retrieve results in your application.
Here’s how to run a simple query with the Python client:
results = ducky.documents.retrieve( index_name="code-memory", query="how do we track customer usage?", top_k=5, rerank=True, ) for doc in results.documents: print(doc.title) print(doc.metadata)
What’s Next
We’ve made the codebase fully searchable in under 50 lines of code. No infrastructure setup. No model tuning. Just a clean semantic layer that lets you ask real questions about your own code and get useful answers back.
This isn’t just about search. It’s about enabling better tools, tighter feedback loops, and assistants that actually understand the systems they’re working in. If you’re building with AI, retrieval is not a nice-to-have. It’s foundational.
Try it on your own codebase, or check out our other resources
📘 Documentation – for detailed setup, search tuning, and advanced features
🧑🍳 Cookbooks – for practical examples and quick-start guides
No credit card required - we have a generous free tier to support builders
Mallards in a Landscape, 1743
Philipp Ferdinand de Hamilton
Mallards in a Landscape, 1743
Philipp Ferdinand de Hamilton