How to build a Legal Document Chat with Ducky.ai
How to build a Legal Document Chat with Ducky.ai


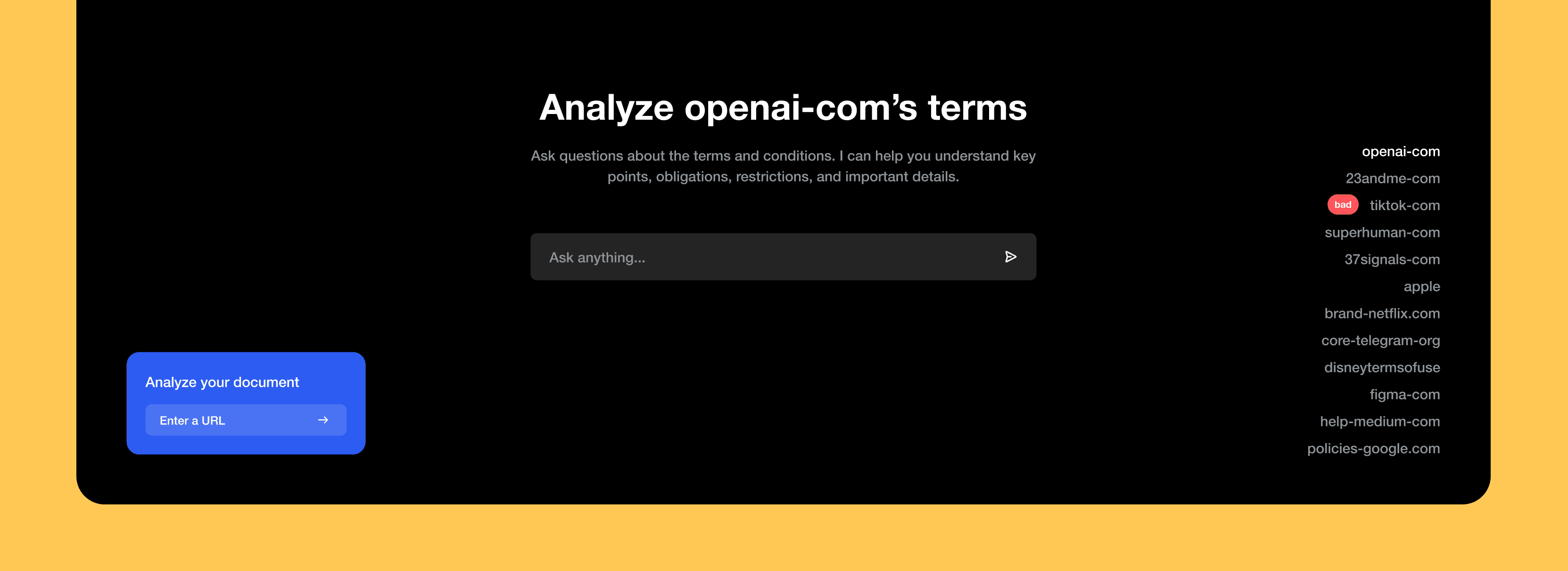
What if anyone could chat with a legal document instead of having to read the whole thing?
I wanted to create a tool where users could paste a link to a legal document and instantly start asking it questions like:
Who owns the content I create?" - Figma ToS
What happens if I violate these terms?" - Apple T&Cs
Today, Fineprint is live and working. It took surprisingly little time to build, thanks to Ducky.
The stack
Here’s the technology that powers Fineprint
Frontend | Next.js - React.js & TypeScript
Backend Scraping | Browserless (headless Chrome)
Semantic Search & Retrieval | Ducky.ai
Language Generation | OpenAI
Hosting | Vercel
How It Works (with some code)
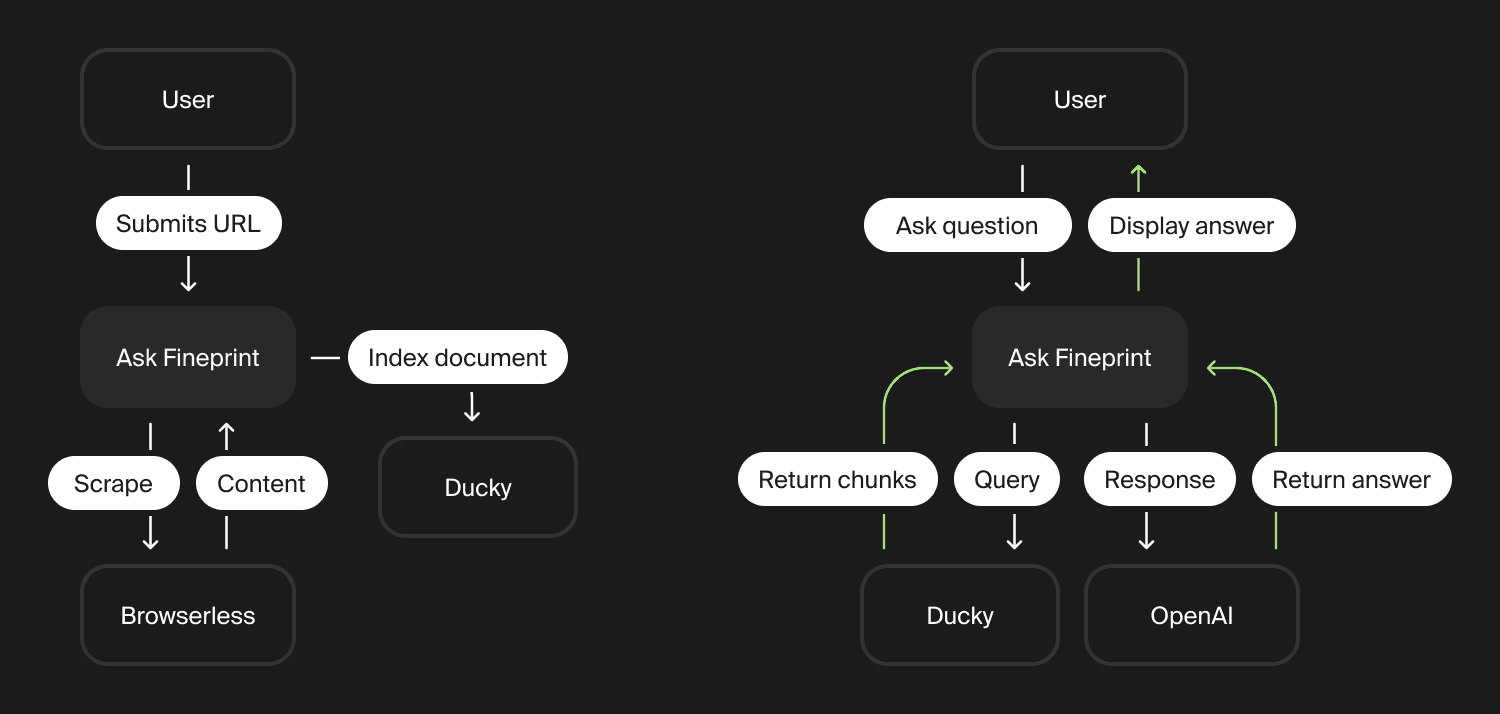
Submitting a document to analyze & index
Step 1 - We first create an index name based on the url and then use Browserless to load and scrape the visible text from the page.
const processDocument = async (url: string) => { setIsProcessing(true) setError(null) const indexName = getIndexNameFromUrl(url) const content = await scrapeContent(url) // Index the document using the nextjs API (code in 2. below) const response = await fetch("/api/document", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ indexName, title: indexName, content, url }) }) if (!response.ok) throw new Error("Failed to index document") return { indexName } }
Step 2 - A new index is created for each document and the extracted “fine print” is indexed using Ducky.ai’s API.
export async function POST(req: Request) { const { indexName, title, content, url } = await req.json() // First create the index await DuckyClient.createIndex(indexName) // Then index the document const result = await DuckyClient.indexDocument({ indexName, title, content, url }) return NextResponse.json(result) } ... export type DuckyIndexDocumentParams = { indexName: string title: string content: string url: string docId?: string } export class DuckyClient { static async createIndex(indexName: string) { const response = await fetch(`${DUCKY_API}/indexes`, { method: "POST", headers: { "x-api-key": DUCKY_API_KEY, "Content-Type": "application/json" }, body: JSON.stringify({ index_name: indexName }) }) if (!response.ok) { throw new Error(`Failed to create index: ${response.body}`) } return response.json() } static async indexDocument(params: DuckyIndexDocumentParams) { const response = await fetch(`${DUCKY_API}/documents/index-text`, { method: "POST", headers: { "x-api-key": DUCKY_API_KEY, "Content-Type": "application/json" }, body: JSON.stringify({ index_name: params.indexName, title: params.title, content: params.content, url: params.url, doc_id: params.docId || "" }) }) if (!response.ok) { throw new Error(`Failed to index content: ${response.statusText}`) } return response.json() } }
Users ask questions about the document
Step 1 - Fineprint retrieves relevant chunks of content from Ducky
const { indexName, question } = await req.json() // From UI // First, get relevant chunks from Ducky const duckyResponse = await DuckyClient.retrieve({ indexName, query: question, alpha: 1, topK: 3 // Get top 3 chunks for better context }) // Prepare context from chunks const context = duckyResponse.chunks.map((chunk) => chunk.content).join("\n\n") ... type DuckyRetrieveParams = { indexName: string query: string alpha?: number topK?: number } static async retrieve(params: DuckyRetrieveParams): Promise<DuckyRetrieveResponse> { const response = await fetch(`${DUCKY_API_BASE}/documents/retrieve`, { method: "POST", headers: { "x-api-key": DUCKY_API_KEY, "Content-Type": "application/json" }, body: JSON.stringify({ index_name: params.indexName, query: params.query, alpha: params.alpha || 1, top_k: params.topK || 1 }) }) if (!response.ok) { throw new Error(`Failed to retrieve documents: ${response.statusText}`) } return response.json() }
Step 2 - The uses OpenAI to synthesise a clear, natural response based on the context.
// Prepare the prompt for OpenAI based on context and question const messages = [ { role: "system", content: "You are a helpful assistant that answers questions about terms and conditions documents. " + "Use the provided context to answer questions accurately and concisely." }, { role: "user", content: `Context from the document:\n\n${context}\n\nQuestion: ${question}` } ] const response = await fetch(OPENAI_API_URL, { method: "POST", headers: { Authorization: `Bearer ${OPENAI_API_KEY}`, "Content-Type": "application/json" }, body: JSON.stringify({ model: "gpt-3.5-turbo", messages, temperature: 0.7, max_tokens: 500 }) }) // Simplified without error handling for readability return { answer: result.choices[0].message.content }
System Flow
Here’s a simple breakdown of how it all connects:
Why Ducky.ai?
Honestly, Ducky was a game changer for this project.
Simple indexing — I didn’t have to build any custom indexing/search engine.
Reliable retrieval — The API delivers semantically relevant context with minimal tuning.
Zero infra management — No hosting embeddings, no worrying about scale.
In a world where retrieval is often the hardest part of building an AI product, Ducky made it easy.
What’s Next
I’m excited to keep building on top of Fineprint:
Support PDFs and uploads (not just URLs)
Highlight referenced sections directly in the document view
Expand offering and categorise documents: include privacy policies, insurance docs, contracts etc.
More sophisticated multi-document search (e.g., compare terms between providers)
Final Thoughts: Anyone Can Build AI Tools Now
This project helped reinforce the idea that you don’t need a giant ML team to build something magical with AI.
With tools like Ducky, OpenAI and Next.js/Vercel, developers can prototype and launch powerful AI-powered tools incredibly quickly.
Fineprint was essentially a 1 day project — imagine what’s possible when we really push the boundaries.
If you’ve been thinking about building something with AI — this is your sign to start.
Try it yourself
What if anyone could chat with a legal document instead of having to read the whole thing?
I wanted to create a tool where users could paste a link to a legal document and instantly start asking it questions like:
Who owns the content I create?" - Figma ToS
What happens if I violate these terms?" - Apple T&Cs
Today, Fineprint is live and working. It took surprisingly little time to build, thanks to Ducky.
The stack
Here’s the technology that powers Fineprint
Frontend | Next.js - React.js & TypeScript
Backend Scraping | Browserless (headless Chrome)
Semantic Search & Retrieval | Ducky.ai
Language Generation | OpenAI
Hosting | Vercel
How It Works (with some code)
Submitting a document to analyze & index
Step 1 - We first create an index name based on the url and then use Browserless to load and scrape the visible text from the page.
const processDocument = async (url: string) => { setIsProcessing(true) setError(null) const indexName = getIndexNameFromUrl(url) const content = await scrapeContent(url) // Index the document using the nextjs API (code in 2. below) const response = await fetch("/api/document", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ indexName, title: indexName, content, url }) }) if (!response.ok) throw new Error("Failed to index document") return { indexName } }
Step 2 - A new index is created for each document and the extracted “fine print” is indexed using Ducky.ai’s API.
export async function POST(req: Request) { const { indexName, title, content, url } = await req.json() // First create the index await DuckyClient.createIndex(indexName) // Then index the document const result = await DuckyClient.indexDocument({ indexName, title, content, url }) return NextResponse.json(result) } ... export type DuckyIndexDocumentParams = { indexName: string title: string content: string url: string docId?: string } export class DuckyClient { static async createIndex(indexName: string) { const response = await fetch(`${DUCKY_API}/indexes`, { method: "POST", headers: { "x-api-key": DUCKY_API_KEY, "Content-Type": "application/json" }, body: JSON.stringify({ index_name: indexName }) }) if (!response.ok) { throw new Error(`Failed to create index: ${response.body}`) } return response.json() } static async indexDocument(params: DuckyIndexDocumentParams) { const response = await fetch(`${DUCKY_API}/documents/index-text`, { method: "POST", headers: { "x-api-key": DUCKY_API_KEY, "Content-Type": "application/json" }, body: JSON.stringify({ index_name: params.indexName, title: params.title, content: params.content, url: params.url, doc_id: params.docId || "" }) }) if (!response.ok) { throw new Error(`Failed to index content: ${response.statusText}`) } return response.json() } }
Users ask questions about the document
Step 1 - Fineprint retrieves relevant chunks of content from Ducky
const { indexName, question } = await req.json() // From UI // First, get relevant chunks from Ducky const duckyResponse = await DuckyClient.retrieve({ indexName, query: question, alpha: 1, topK: 3 // Get top 3 chunks for better context }) // Prepare context from chunks const context = duckyResponse.chunks.map((chunk) => chunk.content).join("\n\n") ... type DuckyRetrieveParams = { indexName: string query: string alpha?: number topK?: number } static async retrieve(params: DuckyRetrieveParams): Promise<DuckyRetrieveResponse> { const response = await fetch(`${DUCKY_API_BASE}/documents/retrieve`, { method: "POST", headers: { "x-api-key": DUCKY_API_KEY, "Content-Type": "application/json" }, body: JSON.stringify({ index_name: params.indexName, query: params.query, alpha: params.alpha || 1, top_k: params.topK || 1 }) }) if (!response.ok) { throw new Error(`Failed to retrieve documents: ${response.statusText}`) } return response.json() }
Step 2 - The uses OpenAI to synthesise a clear, natural response based on the context.
// Prepare the prompt for OpenAI based on context and question const messages = [ { role: "system", content: "You are a helpful assistant that answers questions about terms and conditions documents. " + "Use the provided context to answer questions accurately and concisely." }, { role: "user", content: `Context from the document:\n\n${context}\n\nQuestion: ${question}` } ] const response = await fetch(OPENAI_API_URL, { method: "POST", headers: { Authorization: `Bearer ${OPENAI_API_KEY}`, "Content-Type": "application/json" }, body: JSON.stringify({ model: "gpt-3.5-turbo", messages, temperature: 0.7, max_tokens: 500 }) }) // Simplified without error handling for readability return { answer: result.choices[0].message.content }
System Flow
Here’s a simple breakdown of how it all connects:
Why Ducky.ai?
Honestly, Ducky was a game changer for this project.
Simple indexing — I didn’t have to build any custom indexing/search engine.
Reliable retrieval — The API delivers semantically relevant context with minimal tuning.
Zero infra management — No hosting embeddings, no worrying about scale.
In a world where retrieval is often the hardest part of building an AI product, Ducky made it easy.
What’s Next
I’m excited to keep building on top of Fineprint:
Support PDFs and uploads (not just URLs)
Highlight referenced sections directly in the document view
Expand offering and categorise documents: include privacy policies, insurance docs, contracts etc.
More sophisticated multi-document search (e.g., compare terms between providers)
Final Thoughts: Anyone Can Build AI Tools Now
This project helped reinforce the idea that you don’t need a giant ML team to build something magical with AI.
With tools like Ducky, OpenAI and Next.js/Vercel, developers can prototype and launch powerful AI-powered tools incredibly quickly.
Fineprint was essentially a 1 day project — imagine what’s possible when we really push the boundaries.
If you’ve been thinking about building something with AI — this is your sign to start.
Try it yourself
No credit card required - we have a generous free tier to support builders
Mallards in a Landscape, 1743
Philipp Ferdinand de Hamilton
Mallards in a Landscape, 1743
Philipp Ferdinand de Hamilton