Modern AI means shipping features fast, not building infrastructure. We handle the complexity so you can create experiences your users love.
Ship incredibly fast
Deploy AI search within minutes. Skip the months of building and configuring infrastructure.
All in one platform
We handle all the pieces, you get one surface. It’s the toolkit to shipping AI powered features.
Overwhelming to effortless
Complex AI search packaged into simple APIs. Everything your team needs is ready to use from day one.
Stop stitching together different services for AI search. We handle the entire pipeline in one unified platform.
Multi-modal intelligence
Search seamlessly across text, images, and PDFs. Your content is understood and searchable regardless of its format.
Automated chunking & ranking
Documents are split and optimized for retrieval. Multi-stage reranking ensure the best results surface first.
Advanced metadata support
Power precise searches with filters. Users can narrow results by date, category, tags, or any attribute that matters.
Ship your first AI feature this week. We’ve eliminated all the typical roadblocks.
Zero setup required
Fully managed service that is ready to use. Focus on your product, not the plumbing.
Developer first experience
Intuitive APIs, comprehensive docs, and support for Python and TypeScript SDKs.
Book a demo with our onboarding team or try a search demo in browser.
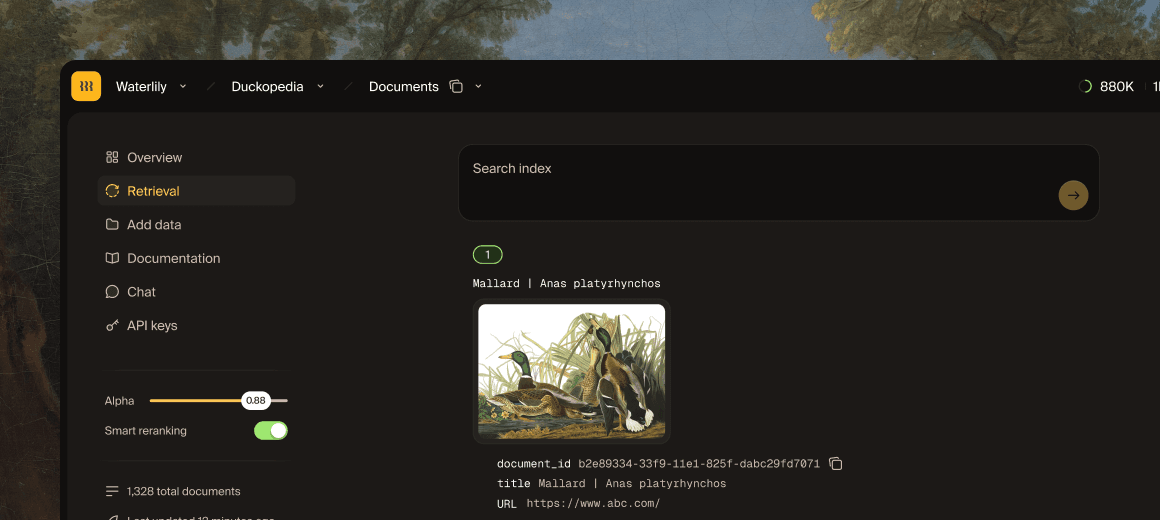

Handles complex searches and improves automatically. No training required.
Understand what you don't want
Ducky handles exclusions and complex conditions naturally. Your team can search the way they think, with all the nuance of what to include and what to leave out.
Self-improving accuracy
The more your team uses Ducky, the better it gets. Search patterns are learned, result rankings improve, and relevance increases automatically over time.
Works seamlessly with today's LLMs and whatever comes next.
Just ask
Agents ask questions and receive complete answers with source attribution. The entire pipeline from search to synthesis is automated.
Cut AI costs
Reduce token usage by up to 80% with context filtering. Your agents only process what's relevant, slashing API bills.
Hallucination reduction
Feed your agents only accurate, relevant context. Eliminate the root cause of AI errors and build reliability into every interaction.
Ducky is free to try with zero commitment.
Trial
Only pay when you need more
100k index tokens
100k retrieval tokens
$0
Launch
For when its time to go live
3M index tokens each month
3M retrieval tokens each month
$0.014 per additional 1K index tokens
$0.079 per additional 1K retrieval tokens
Dedicated support via Slack
$290